understand what a natural language processing pipeline is
know what dependency parsing and parse trees are
have used a tool created using NLP Compromise, a Javascript library
have create a program using Natural Language Tool Kit (NLTK) or NLP Compromise
Activity 1: General introduction
Read this to understand the concepts of NLP, POS tags and parse trees
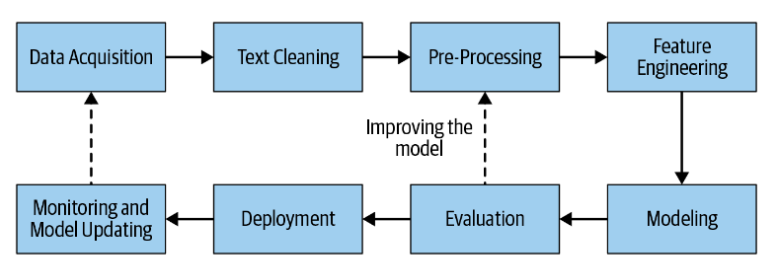
Natural language processing pipeline
A natural language processing (NLP) system is usually called an NLP pipeline. This because it usually involves several stages (steps or layers) of processing. The pipeline is one directional. There is an input (natural language) and an output (processed text). Simply put, NLP is applying artificial intelligence to human languages.
POS tagging is the act of labelling words with a particular part of speech. The common parts of speech are noun, verb, adverb and adjective. However, most POS taggers use a much large set of tags. The most popular POS tagset has 36 tags. NLP pipelines that aim to map syntax or disambiguate meanings often use this layer. The Penn treebank tagset is shown in the table below.
CC Coordinating conjunction
CD Cardinal number
DT Determiner
EX Existential there
FW Foreign word
IN Preposition or subordinating conjunction
JJ Adjective
JJR Adjective, comparative
JJS Adjective, superlative
LS List item marker
MD Modal
NN Noun, singular or mass
NNS Noun, plural
NNP Proper noun, singular
NNPS Proper noun, plural
PDT Predeterminer
POS Possessive ending
PRP Personal pronoun
PRP$ Possessive pronoun
RB Adverb
RBRAdverb, comparative
RBS Adverb, superlative
RP Particle
SYM Symbol
TO to
UH Interjection
VB Verb, base form
VBD Verb, past tense
VBG Verb, gerund or present participle
VBN Verb, past participle
VBP Verb, non-3rd person singular present
VBZ Verb, 3rd person singular present
WDT Wh-determiner
WP Wh-pronoun
WP$ Possessive wh-pronoun
WRB Wh-adverb
If you are keen on learning this tagset. Try out this timed game.
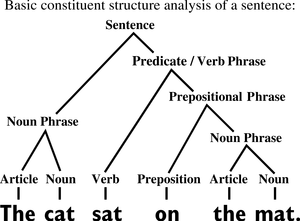
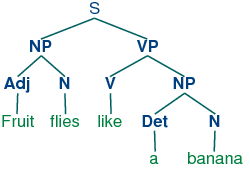
Dependency parsing and parse trees
NLP pipelines can be used for many tasks. Dependency parsing is one task that is often used as one step or layer. Dependency parsing uses the part-of-speech tags assigned to words in a previous layer and creates a parse tree. The parse tree identifies a sentence and splits up the sentence sequentially. This shows the relationship between the words. During this process, trees of parent and child words are created. Parse trees are used in many NLP tasks. However, it needs to be remembered that any errors in the POS tags will affect the accuracy of the parse tree. The example below shows how a simple sentence can be broken down and the relationship between individual words mapped out on to a parse tree.
Source: Wikicommons
Activity 2: NLP Compromise
Watch and listen to this animated explanation of the JavaScript library NLP Compromise (17 min 52 sec). This library is recommended if you code in JavaScript. If you work in Python, you can omit this activity and focus on NLTK.
Activity 3: Identifying tense using NLP Compromise
Try out this online tool created by a student team in 2019. This project was awarded grade A. Great job! NLP compromise is a JavaScript library that mimics a full-blown pipeline. It is completely rule-based. The problems in this tool all stem from NLP Compromise inaccurately tagging parts of speech.
Activity 4: Experiment with NLP Compromise
Read this explanation of NLP Compromise written by its creator, Spencer Kelly. There are a couple of tutorials listed at the bottom of the page that should help you get started.
On its Github page you can find useful functions in the Readme section.
Activity 5: Natural Language Tool Kit (NLTK)
The Natural Language Tool Kit (NLTK) is one of the most popular libraries for creating NLP pipelines. There are many tutorials online to show you how to get started. For those who prefer a video introduction, check out the first video in this playlist. The topic is tokenizing. Sentdex is a popular programming YouTuber with over 900k subscribers.
Watch and listen to this short introducttion to using NLTK with Python.
Knowledge and application
Activity 6: Problem solving: NLP pipeline in Python (or NLP Compromise)
Create a NLP pipeline using NLTK to process the text below. If you prefer to use JavaScript, you can use NLP Compromise instead.
"Two frogs, a father and his son, accidentally fell into a bucket of milk. They started swimming for their lives. They swam for a long time, but there seemed no hope of their getting out. The father soon gave up and drowned. The son carried on swimming. During this time, the milk had begun to form a ball of butter. Using this island of butter as a platform, he managed to hop out of the bucket."
Solve as many of these problems as possible.
Part-of-speech (POS) tagging: identify all the nouns.
Text extraction: classify the nouns into uncountable, singular or plural.
Count features: identify and count a language feature.
Visualize text: identify and highlight a particular feature.
Manipulate text: identify and replace a different feature.
Add comments in your code to show (1) the function of each important line of code and (2) the source of any code copied from tutorials, etc.
Submit your code, or a link to your code online via ELMS
Enjoy an adaption of this story in "Catch me if you can".
Review
Make sure you can explain the following 8 terms simple English:
natural language processing (NLP)
NLP pipeline
part-of-speech (POS) tagging
POS tagset
dependency parsing
parse tree
NLP Compromise
Natural Language Tool Kit (NLTK)
Running count: 71 of 71 pattern-related concepts covered so far.
 Awareness and defense
Awareness and defense